AI Models for Decompiling Assembly Code

Introduction
The challenge of converting low-level assembly code back into human-readable source code is a cornerstone problem in reverse engineering. In this post, we summarise recent work done at RevEng.AI that addresses this challenge through the development of foundational AI models designed for decompilation. As we shall see, this approach is able to produce surprisingly accurate code that more closely resembles human-written source-code than existing rules-based decompilers. Whilst these models currently still have limitations (which we discuss), they offer an exciting new approach that has the potential to greatly aid reverse engineers and security analysts.
The Importance of Decompiling Assembly Code
Source code written by humans is typically far more comprehensible than the raw assembly code found in binaries. The process of decompilation - translating this low-level assembly code back into human-readable source code - can therefore play a vital role in reverse engineering and software security analysis. In particular, it plays a crucial role in:
- Malware Analysis - Enabling security researchers to understand and counter malicious software.
- Legacy Code Maintenance - Recovering source code from old, compiled software.
- Vulnerability Research - Identifying security flaws in closed-source applications.
- Intellectual Property Protection - Verifying unauthorised use of proprietary code.
However, decompilation faces inherent challenges. The compilation process strips away valuable information such as variable names and transforms higher-level code structures like loops and conditionals in a fundamentally irreversible way, making perfect reconstruction impossible. While established tools like Ghidra and IDA Pro can reconstruct a pseudo code equivalent of the disassembly, it can often be difficult-to-understand or bears little resemblance to human-written source code.
Traditional vs. AI-Powered Decompilation
Traditional decompilers rely on predefined rules and heuristics, using techniques like control flow analysis and type inference to reconstruct higher-level code. Whilst sophisticated, these systems often struggle with complex code patterns and produce literal, convoluted translations.
AI-powered decompilation offers a fundamentally different approach. Instead of following rigid rules, modern AI models learn patterns directly from large datasets. This has two key advantages:
- The output will naturally resemble human-written code, including natural programming constructs and idioms that make better use of the surrounding context, since the model is trained to mimic real source code examples.
- Not limited by handcrafted rules - everything required for good decompilation can be learned automatically, including things that are difficult to capture in a set of rigidly defined rules. This has the potential to improve the semantic accuracy of the decompiled code.
An Illustrative Example
Let's start with an example taken from the HumanEval benchmark[4], which is a collection of code solutions to programming problems and corresponding tests that need to pass. On the left we have the original source code for a function that takes two lists of integers, along with the sizes of those lists, and then counts the number of even numbers in both lists combined. If that number is more than or equal to the size of the first list, it returns "YES", otherwise it returns "NO". The model takes the function's assembly code (extracted and preprocessed with our internal toolkit) and feeds it into the AI model, which then produces its best guess at replicating the original source code.
Original Source Code
const char* func0(int *lst1, int size1, int *lst2, int size2) {
int num = 0;
for (int i = 0; i < size1; i++)
if (lst1[i] % 2 == 0) num += 1;
for (int i = 0; i < size2; i++)
if (lst2[i] % 2 == 0) num += 1;
if (num >= size1) return "YES";
return "NO";
}Ghidra Decompilation
undefined * func0(uint *param_1,int param_2,long param_3,int param_4)
{
uint *puVar1;
int iVar2;
undefined *puVar3;
long lVar4;
if (param_2 < 1) {
iVar2 = 0;
if (param_4 < 1) {
return &DAT_00002007;
}
}
else {
puVar1 = param_1 + (ulong)(param_2 - 1) + 1;
iVar2 = 0;
do {
iVar2 = iVar2 + (uint)((*param_1 & 1) == 0);
param_1 = param_1 + 1;
} while (param_1 != puVar1);
if (param_4 < 1) goto LAB_000014ff;
}
lVar4 = 0;
do {
iVar2 = iVar2 + (uint)((*(uint *)(param_3 + lVar4 * 4) & 1) == 0);
lVar4 = lVar4 + 1;
} while ((int)lVar4 < param_4);
LAB_000014ff:
puVar3 = &DAT_00002007;
if (iVar2 < param_2) {
puVar3 = &DAT_00002004;
}
return puVar3;
}AI Decompiler Output
char *
func0(
int *a,
int a_len,
int *b,
int b_len
)
{
int count = 0;
for (int i = 0; i < a_len; i++) {
if (a[i] % 2 == 0) {
count++;
}
}
for (int i = 0; i < b_len; i++) {
if (b[i] % 2 == 0) {
count++;
}
}
if (count < a_len) {
return "NO";
}
else {
return "YES";
}
}
Whilst the variable names and formatting are slightly different, we can see that the AI decompiler is able to perfectly replicate the logic of this function in a way that it is relatively simple for an experienced human programmer to understand. On the other hand, the Ghidra decompilation to pseudocode is much more difficult to interpret. Firstly, it does not fully infer the correct types in the function signature, and then the series of operations it performs is much harder to follow, including a number of do-while loops and a goto statement, as well as multiple nested type castings and bit-wise operations. The variable names it returns are also very generic and not at all informative, whilst the variable names the AI decompiler uses are much more natural.
AI Decompilation - Problem Setup, Dataset & Training
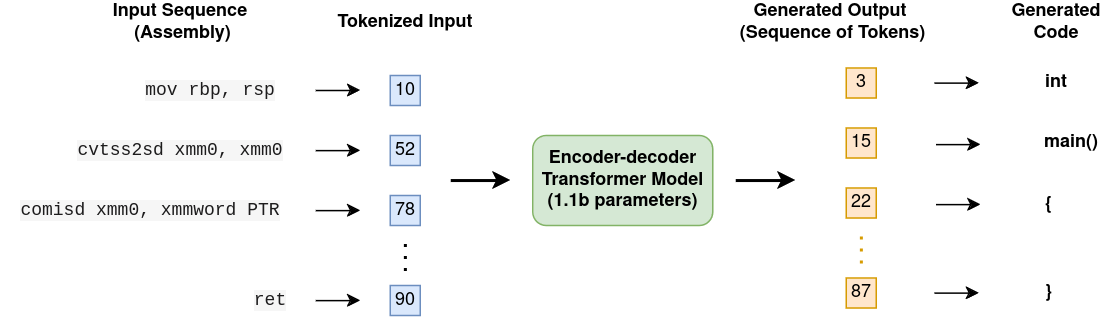
At a fundamental level the problem of decompilation can be posed as a "sequence-to-sequence" translation problem. We have an input (the extracted assembly code for a given function in a binary) and we have a desired output (the original source code), and so we want to train a generative model that can take an input and generate a plausible corresponding output. To do this, we leverage tools/model architectures that have found great success in the field of natural language processing (NLP) for translation tasks - specifically encoder-decoder transformer models. We take inspiration from a number of existing projects [1] [2], although our data collection, preprocessing, tokenisation and model architecture differs significantly from these works.
To train a model of this kind, we need to generate a dataset of pairs of assembly inputs and corresponding source code targets. We then tokenize these datasets, converting each input into a sequence of tokens (integers), which can be fed into the transformer architecture. The transformer is trained end-to-end to optimise a loss function that encourages the sequence of output tokens it produces to be as close to the target output (for a given input) as possible. Whilst this is a simple, almost "brute-force" approach to solving the problem, experience has shown that when run at scale with large models and large datasets the performance can be remarkably good.
When training a large-scale generative AI model, the most important component is the dataset. The size, diversity and quality of the data used for training is absolutely critical for maximising final performance. We also need to take great care in the way that we represent both the assembly code and the target source code, standardising the formatting and inserting special tokens in place of function calls/custom types to help alleviate issues related to hallucination.
We experimented with a variety of model architectures and preprocessing/tokenisation strategies. Our best performing model currently is an encoder-decoder transformer with 1.1 billion parameters, trained on our dataset of ~33 million unique extracted assembly/C source code function pairs. These consist of ~12 million unique C functions compiled using different optimisation settings and different compilers (GCC and Clang). Rather than fine-tuning an existing model, we perform our own pre-training, since we felt that the difference between assembly and natural language/other coding languages is quite significant. Whilst it is likely that larger models would improve performance even further, we wanted to constrain the size of the model somewhat to ensure it can be served efficiently on the RevEng.AI Binary Analysis platform.
Although work done on the LLM4Decompile project has suggested that performance can be improved (at least on a particular benchmark) by using the Ghidra decompilation as input to the model rather than the raw assembly code, we chose not to do this. The reason is that although it is likely in many cases that converting decompiled C into "standard" source code is easier than doing so directly from the binary, it is also the case that Ghidra quite often makes irreversible mistakes. In such cases, this fundamentally limits how good the decompilation can be. We also find that by carefully processing and curating the datasets and optimising the tokenisation strategy we can get performance that exceeds the performance of the comparable LLM4Decompile models (see HumanEval benchmark results below). However, it is an interesting question whether using another form of intermediate representation as input (with less information loss) could improve the performance of the model further, and is something we are currently exploring.
Annotated Examples
In this section we show and annotate a selection of examples. Note that we have omitted the processed input, and just show the original source code alongside what the AI decompiler produces (although it is important to emphasise that the model never uses any of this original source code as part of its input). Each example has some annotations discussing what the function does and noting anything of interest in the AI decompiler's attempt to reconstruct the function.
Original Source Code
AI Decompiler Output
Annotation
HumanEval Benchmark Performance
A standard benchmark for code generation tasks is the HumanEval benchmark, which is a set of programming challenges and tests that a solution to each challenge must pass. Following [1] , we use a version of HumanEval where the solutions are converted to C. Importantly, all of these tasks only use standard library functions and are therefore relatively easy to compile with GCC or Clang.
The evaluation works by compiling the original solutions into binaries (with multiple optimisation levels), extracting the assembly code for these functions, feeding this into the AI decompiler and then substituting the decompiler output in place of the original function implementation to see if the tests still pass. Note that this is quite a challenging and unforgiving benchmark, in the sense that a single mistake will be punished just as much as code that is completely wrong. Establishing evaluation protocols with a stronger feedback signal (i.e. not just a binary success or failure) is something we are actively thinking about here at RevEng.ai, but is left for future work.
The table below shows the results on this benchmark. We include a breakdown of the fraction of generated code that successfully passes the original tests in total and for each of the compiler optimisation levels considered. We compare our results against Ghidra and against a variety of models released by the LLM4Decompile project. Some of these take in assembly code as input, whilst some take in Ghidra's attempted decompilation instead (this is noted below each model).
| Fraction of Generated Code that Passes all Tests | |||||
|---|---|---|---|---|---|
| Total | O0 | O1 | O2 | O3 | |
| RevEng AI Decompiler [1.1b params, assembly] |
0.475 | 0.764 | 0.405 | 0.384 | 0.339 |
| Ghidra | 0.201 | 0.348 | 0.165 | 0.152 | 0.140 |
| LLM4Decompile [1.3b params, assembly] |
0.273 | 0.472 | 0.206 | 0.212 | 0.202 |
| LLM4Decompile [6.7b params, assembly] |
0.454 | 0.681 | 0.395 | 0.367 | 0.372 |
| LLM4Decompile [1.3b params, Ghidra decomp] |
0.460 | 0.689 | 0.372 | 0.409 | 0.372 |
| LLM4Decompile (best) [9b params, Ghidra decomp] |
0.649 | ? | ? | ? | ? |
We can see that the RevEng AI Decompiler significantly outperforms both Ghidra[3] and the most comparable LLM4Decompile model (1.3b params with assembly input), even outperforming the 6.7b parameter assembly input model. It also slightly outperforms the model of comparable size that takes as input the Ghidra decompiled C, and is only beaten here by a model that is substantially bigger.
Conclusions
Our work on AI-powered decompilers has demonstrated remarkable promise, and we're actively integrating this technology into our platform for users to experiment with. Through careful dataset curation and innovative training approaches, we've shown that a relatively compact model can produce high-quality decompilations that rival or exceed traditional approaches. Whilst the model is by no means perfect and still makes mistakes, we believe this approach has the potential to lead to significantly more reliable and user-friendly decompilers in the future.
Looking ahead, we're pursuing several exciting avenues for improvement:
- Expanding our dataset and processing pipeline to support C++ and other languages, while incorporating compilers from additional platforms such as Windows.
- Exploring alternative intermediate representations as model inputs, potentially replacing raw assembly code with more structured formats.
- Developing more sophisticated evaluation metrics that go beyond simple pass/fail testing.
- Integrating semantic correctness feedback directly into the training process to enhance output quality.
Our AI Decompiler is available for existing RevEng.AI users immediately. For new users wanting to gain access, sign-up and join the waitlist here.
Footnotes/References
SLaDe: A Portable Small Language Model Decompiler for Optimized Assembly, Armengol-Estapé et. al (Paper) ↩︎
Note: the comparison with Ghidra is not entirely fair, since Ghidra produces a kind of pseudo-C code rather than standard C and may include e.g. references to addresses of strings and doubles which will not easily recompile/re-execute even if semantically the code is essentially correct. Although equally, this can be seen as a limitation of Ghidra. ↩︎